|
This week I created some scripts to pull specific information from the language data provided. Some of this information included the lengths of the sentences and what part of speech (POS) relates to what other POS and how, whereas last week I just looked at how they related and not what the relationships were between. As for the lengths of the sentences I have created some graphs from the data, this first graph has all the data for all of the languages on it: 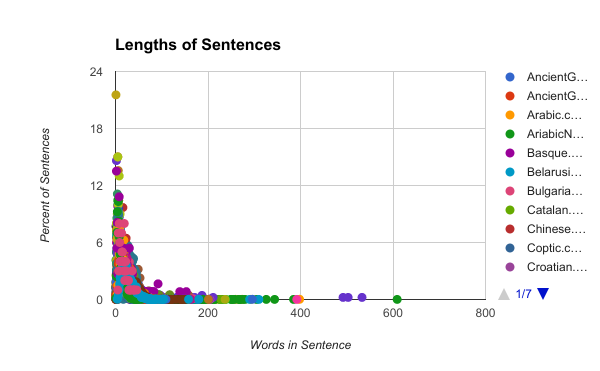 This graph looks quite messy because of the 70 languages on the graph so instead lets look at some of the language groups I looked at last week: 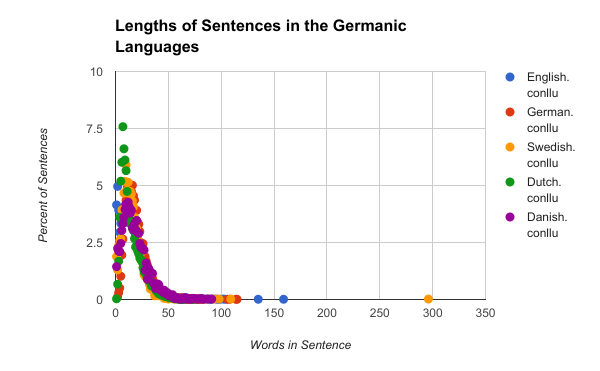 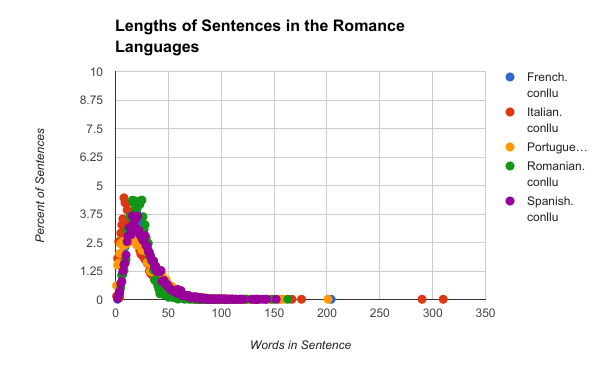 By looking at the Germanic and Romance languages you can see that on the graph for the Germanic languages the peak is slightly earlier, higher, and thinner than the Romance languages. This type of analysis for sentence lengths, trigrams (groups of three juxtaposed POS labels), POS relationships and other aspects of the sentence will allow us to group languages by similar parts and group certain parts to better parse the surprise languages.
0 Comments
|
