|
This week I was able to take the previous parsing model I trained on 2,000 English sentences and trained it on an additional 10,000 sentences. With this additional training the program becomes more accurate in parsing sentences. If we take a look at the same sentence from last week (The boy walked across the street.) and run it through the new parser we do not get the problem that the lemma of walked is walke instead the program correctly states it as walk. The other thing I did this week was creating a way to better visualize the output of the parsing program. To remind you of the output of the program here is the output of the same sentence with the better trained model: 1 The the DET DT Definite=Def|PronType=Art 2 det _ _ 2 boy boy NOUN NN Number=Sing 3 nsubj _ _ 3 walked walk VERB VBD Mood=Ind|Tense=Past|VerbForm=Fin 0 root _ _ 4 across across ADP IN _ 6 case _ _ 5 the the DET DT Definite=Def|PronType=Art 6 det _ _ 6 street street NOUN NN Number=Sing 3 nmod _ SpaceAfter=No 7 . . PUNCT . _ 3 punct _ _ And here is the more visually appealing output from the brat annotation: 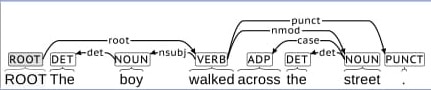 While this output doesn't have all of the information that the original does, it shows most of the information that a person would want from a sentence. This is fine since the computer wouldn't be getting its information from this annotation but rather from the raw output. Now that I can automatically convert to this new visual output I won't have to post the ugly raw output.
0 Comments
|
